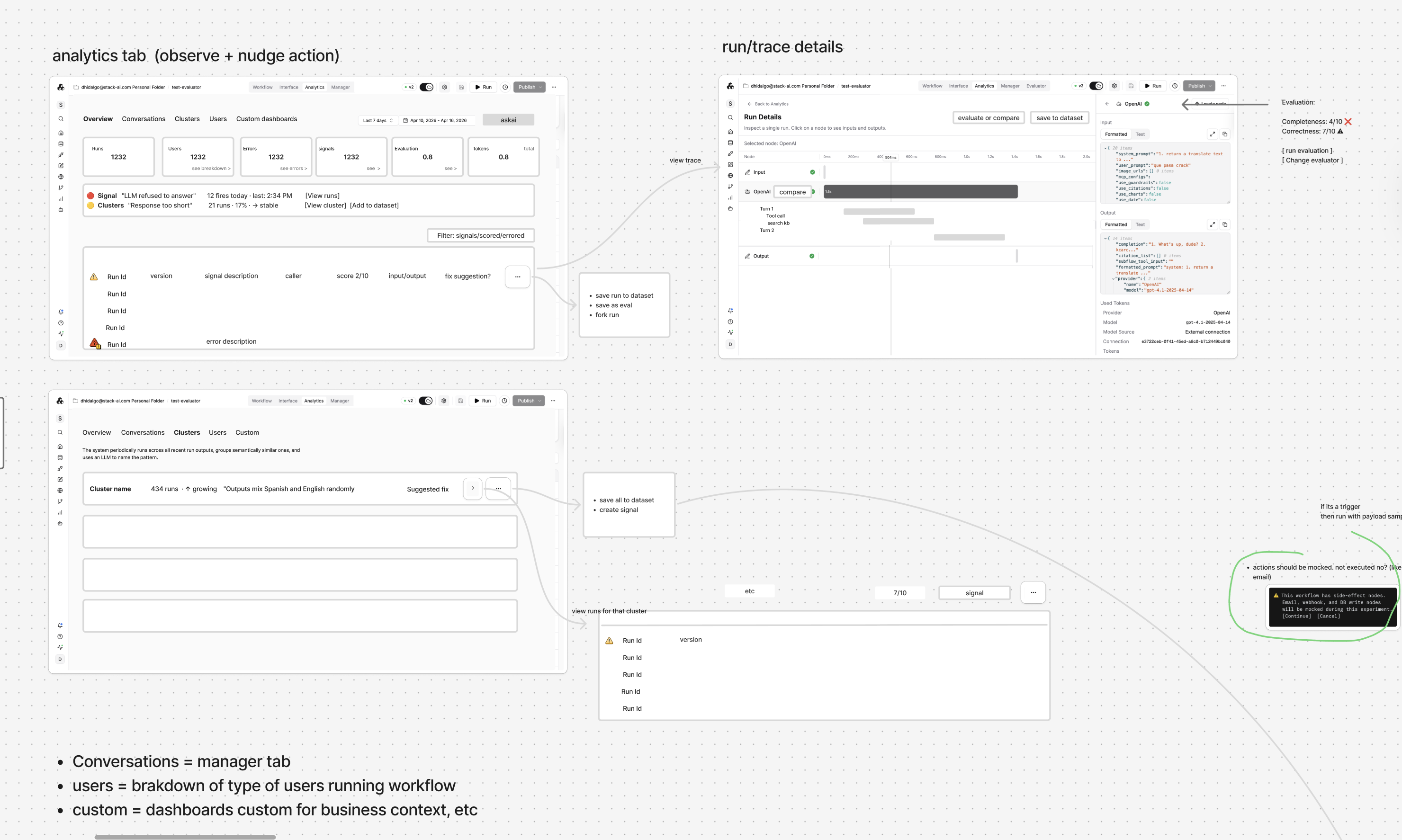
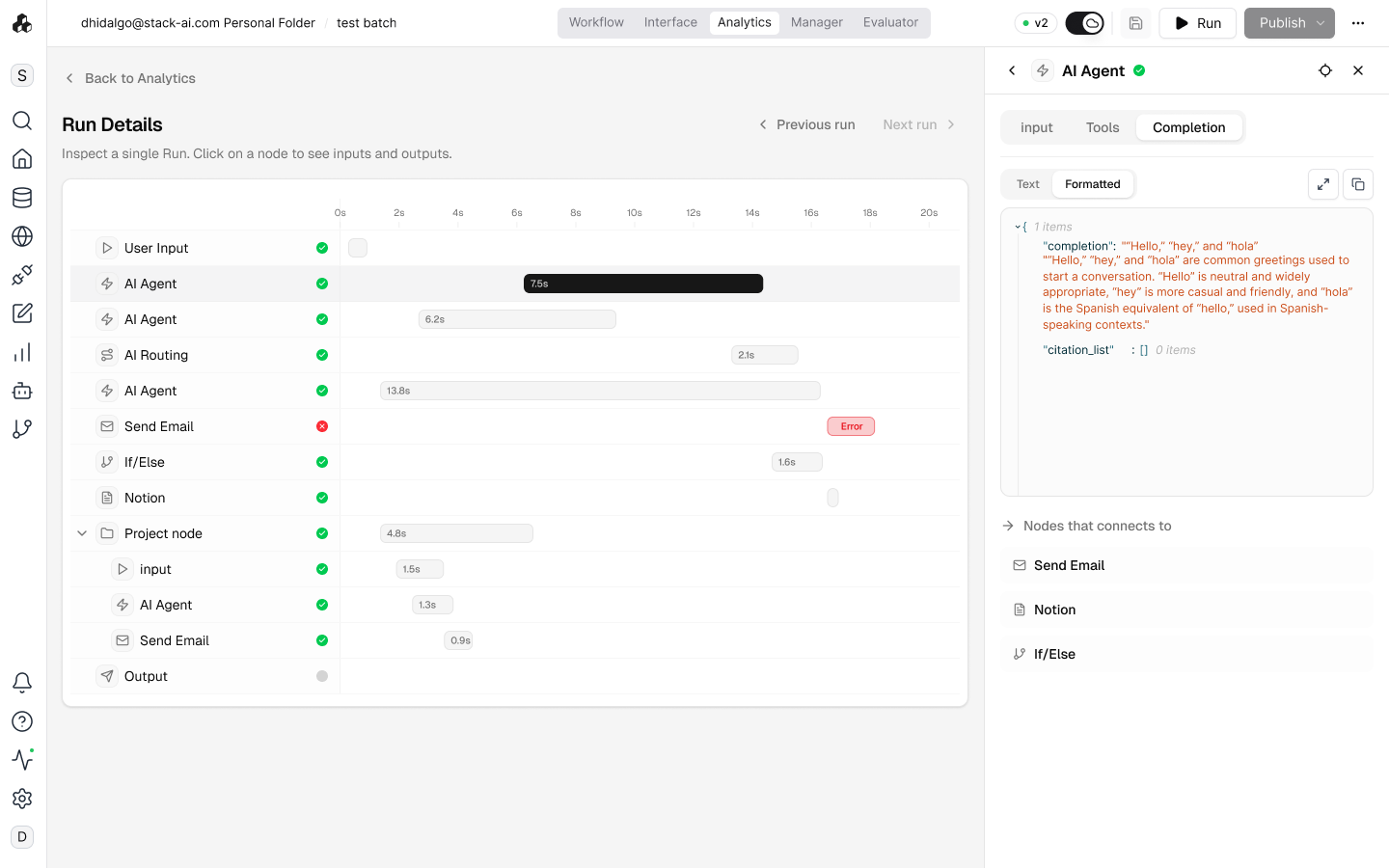
Auditability and evaluation
of agentic workflows.
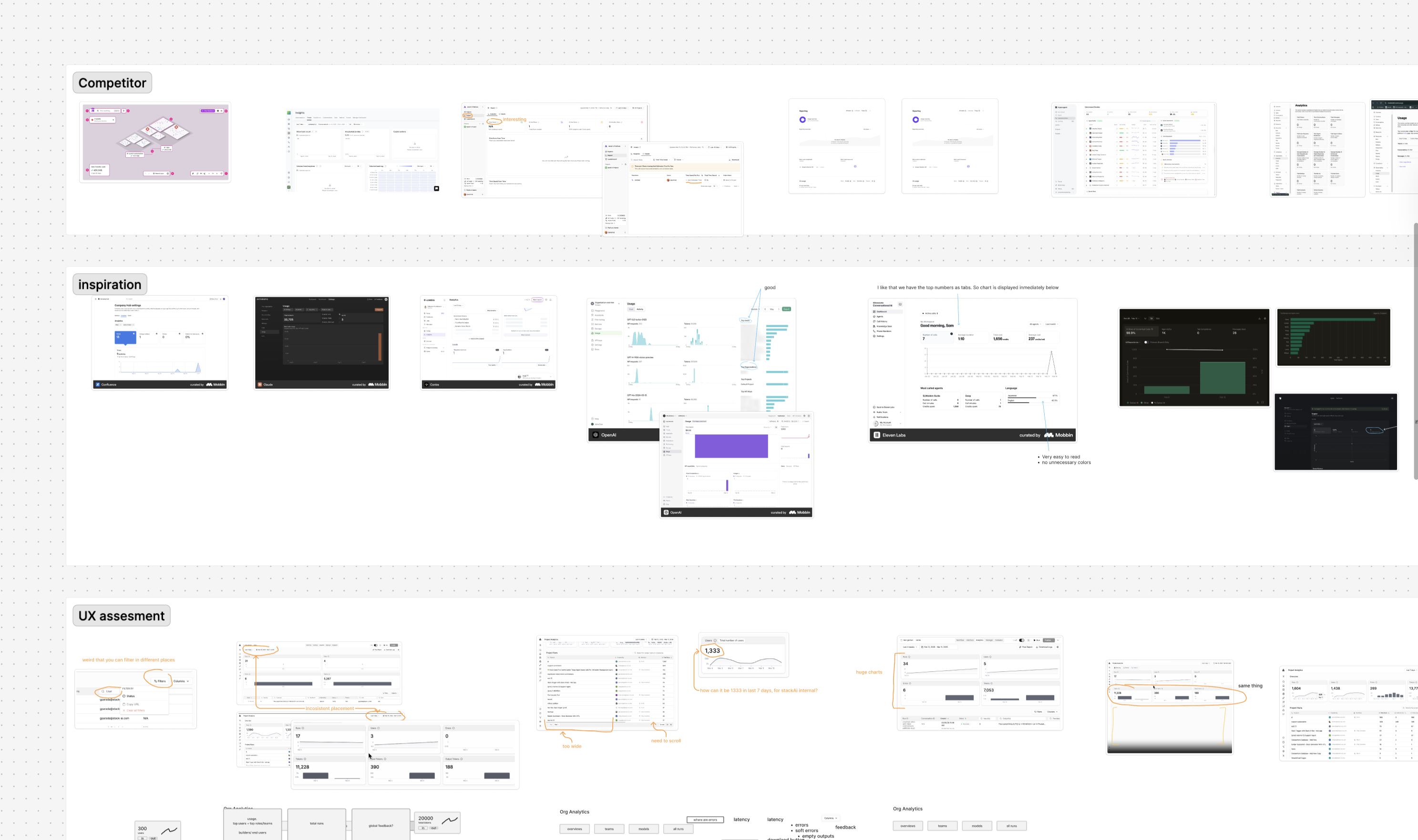
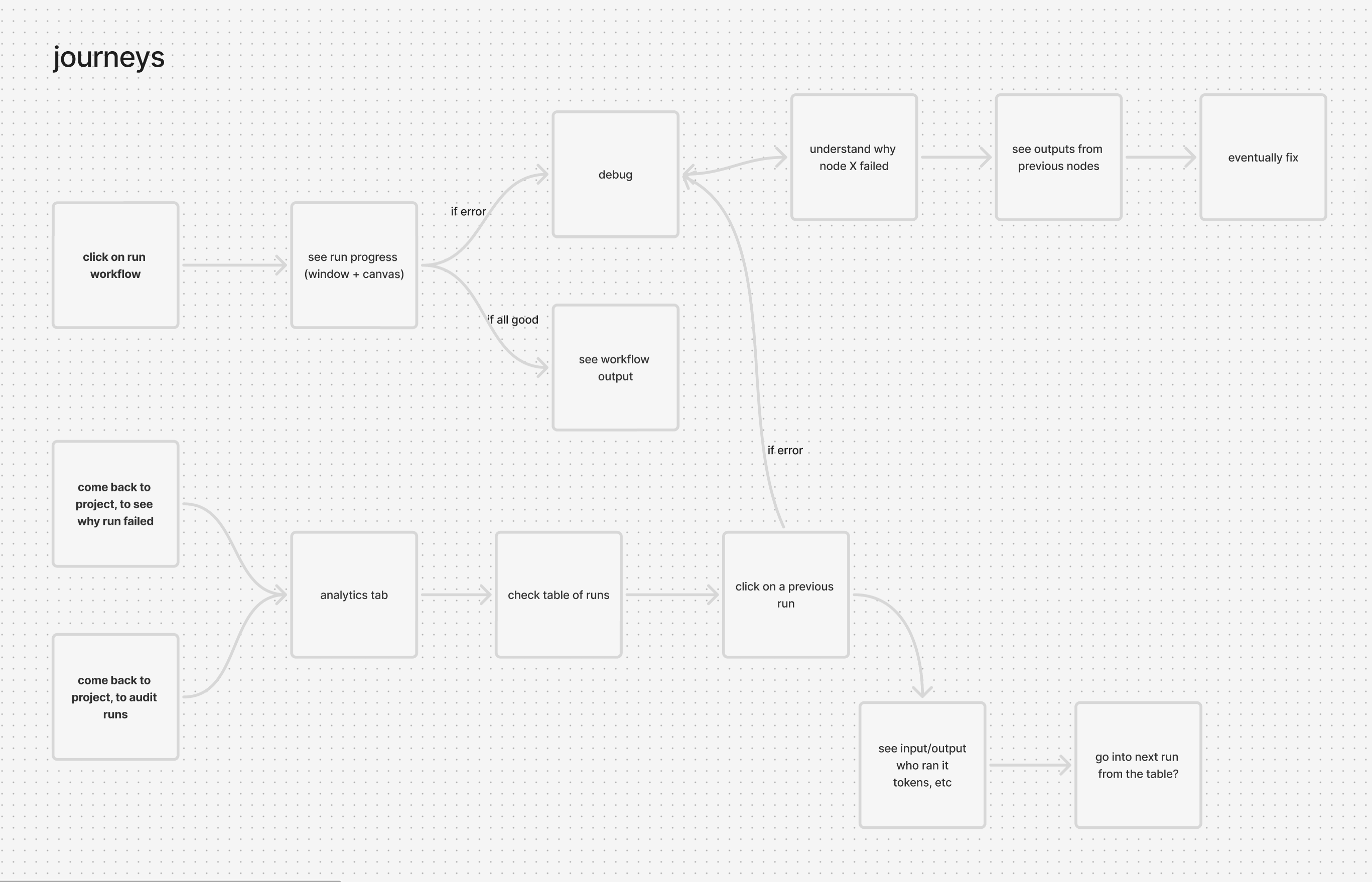
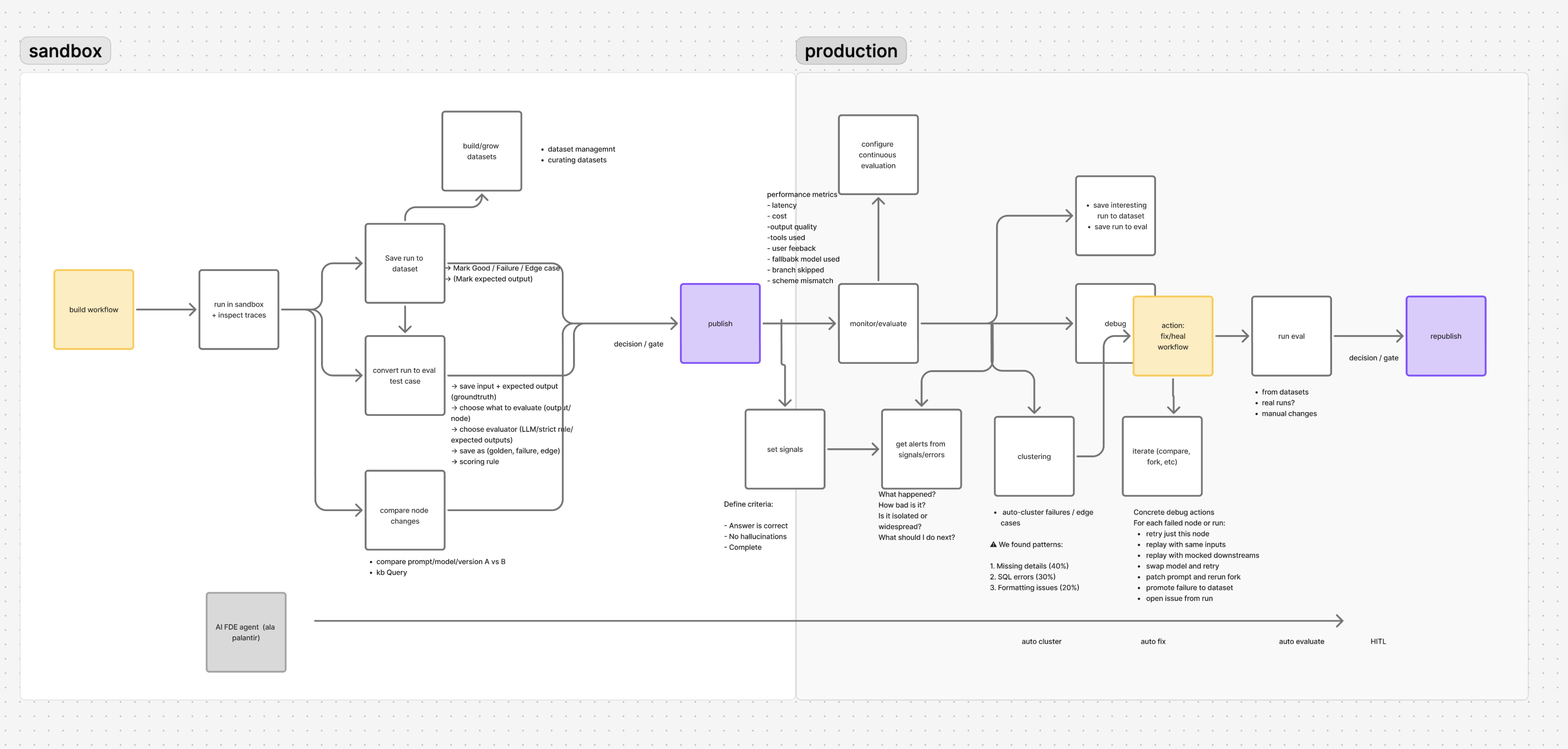
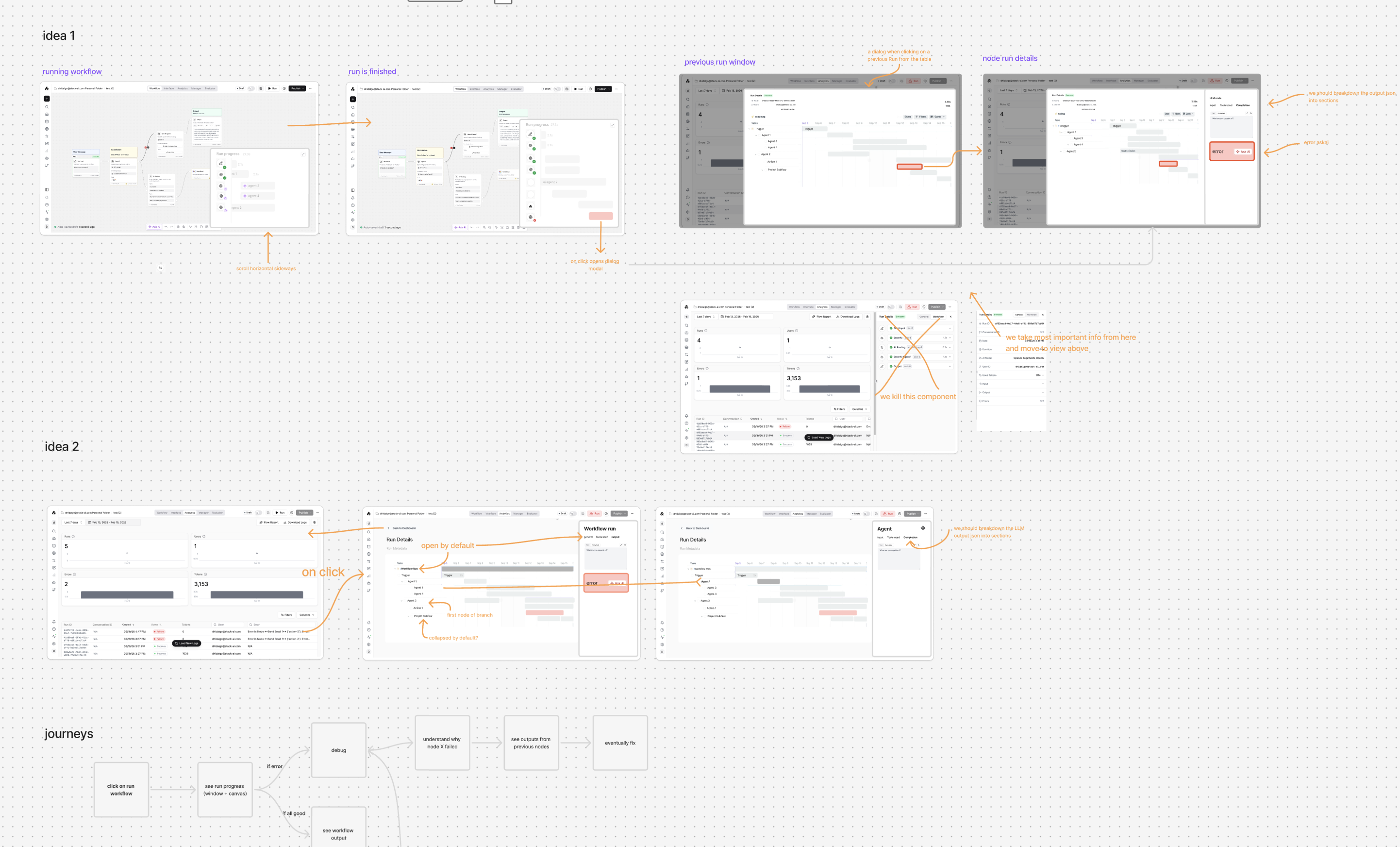
Two interconnected initiatives to transform StackAI's observability and quality story, org-wide analytics and continuous evaluation as a deployment gate.
Impact
Usage grew 5.5× with 3× deeper user engagement. Runs drill downs drove 22,000+ views in six months.